










Continue
Empowering AI Native
Businesses Worldwide
With the mission of "creating intelligence and exploring new frontiers " and the vision of " empowering AI native businesses worldwide ", DataCanvas is the leader in artificial intelligence foundation software in China.
DataCanvas is committed to providing users with AI foundation services through independently developed AI foundation software product series and solutions, helping users easily complete the two-way empowerment of models and data in the digital transformation, accelerating the realization of large-scale application of enterprise-level AI.

Intelligent Computing Revolution:
Reshaping Future Computing
2024 DataCanvas AIDC Operation System Launch Event
The Momentous Launch of
DATACANVAS AIDC OS
Refactoring Computing and Defining A Completely New Computing Infrastructure
Artificial Intelligence
Foundation Software
DataCanvas AIFS

Intelligent Computing Revolution:
Reshaping Future Computing
2024.04
The Momentous Launch of
DATACANVAS AIDC OS
2024.04
Artificial Intelligence
Foundation Software
2023.11

 AI Foundation Software
AI Foundation Software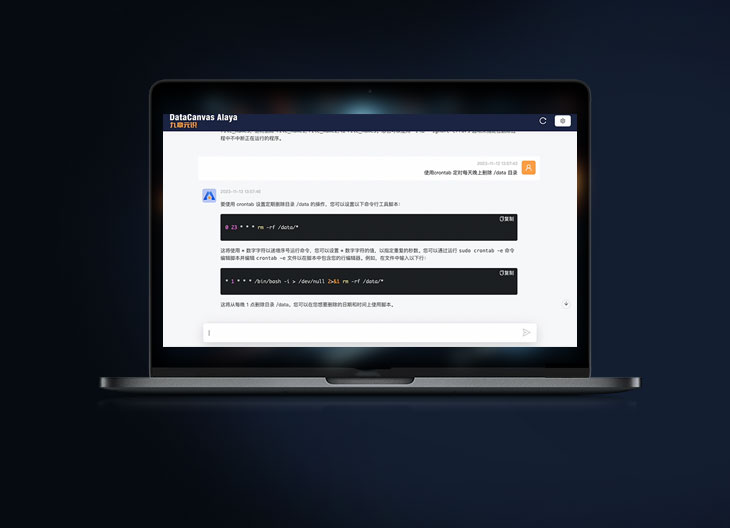



 Engine of Vector Ocean
Engine of Vector Ocean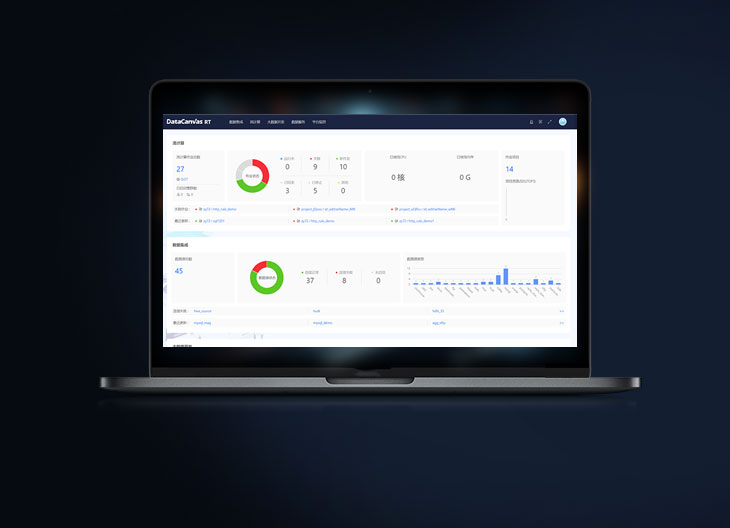


 AIFS
AIFS
 AIDC
AIDCAs an industry-leading artificial intelligence application construction infrastructure platform, AIFS covers the training, fine-tuning, compression, deployment, inference and monitoring of large models as well as the entire life cycle of small models. It provides a set of tools for data scientists, application developers, and business experts so that people in different roles can collaborate with each other to easily process and use data to develop, train, and deploy models of any scale.
DataCanvas Alaya is a self-developed "general + industry" white box large model matrix by DataCanvas. It provides a series of pre-trained large models with different configurations and parameters and has the industry's cutting-edge capabilities and technologies. The Alaya-7B series foundation and chat models in the matrix are open source large models.MORE
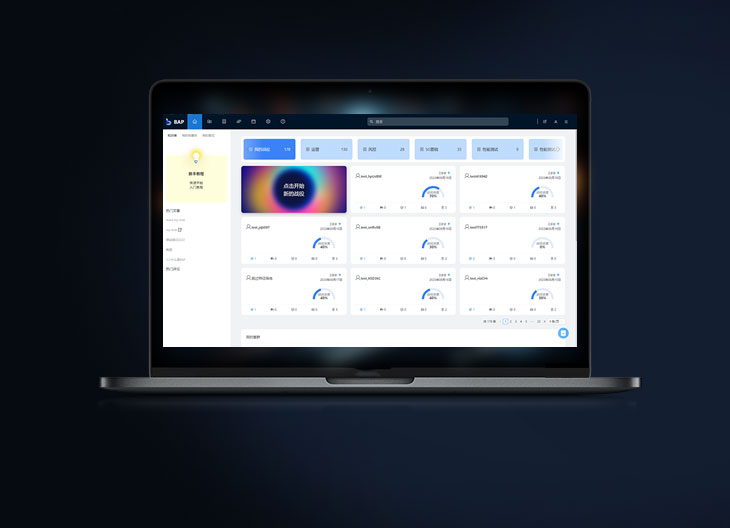
TableAgent is a LLM agent powered by DataCanvas Alaya Foundation Model and support privatized deployment of enterprise-level data analysis. TableAgent is capable of strong intention understanding capabilities,AI modeling capabilities and data insights capabilities. After understanding user’s intentions, TableAgent autonomously utilizes advanced modeling technologies such as statistics, machine learning, and causal inference to uncover the value of given data, and further provide insightful analysis and action guidance.MORE
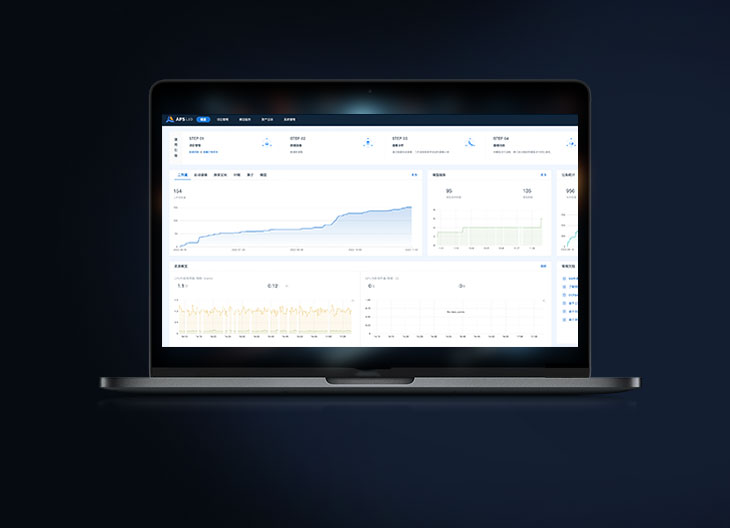
DataCanvas APS (AI Infrastructure Platform Service) provides data scientists, application developers and business experts with a set of tools to process multi-source heterogeneous data autonomously and easily, develop, train and deploy machine learning and deep learning models at any scale quickly and efficiently, to open up the last mile of enterprise-level "large + small" model applications.MORE
DingoDB is a distributed real-time multimodal database that combines the characteristics of data lakes and vector databases, supporting the storage of multimodal data types (Key Value, PDF, audio, video, etc.). At the same time, it uses structured and unstructured fusion analysis and calculation technology to achieve efficient management and retrieval of multimodal data.MORE
DAT is an automated machine learning tool stack independently developed by DataCanvas, consisting of a series of interrelated tools used to complete different machine learning tasks. Its aim is to enhance the technical capabilities of various machine learning platforms that users already have, reduce the threshold for enterprises to use AI and other data science technologies, and comprehensively release the ability of automated machine learning (AutoML) to various fields. MORE
As the "neural center" of intelligent computing centers, the DATACANVAS AIDC operating system is driven by AI usage capabilities, focusing not only on the effective management and utilization of hardware resources, but also on how to better meet the core computing power needs of end users: through intelligent scheduling and optimized configuration, the AIDC OS provides available, user-friendly, and economical computing power to users.
As the "neural center" of intelligent computing centers, the DATACANVAS AIDC operating system is driven by AI usage capabilities, focusing not only on the effective management and utilization of hardware resources, but also on how to better meet the core computing power needs of end users: through intelligent scheduling and optimized configuration, the AIDC OS provides available, user-friendly, and economical computing power to users.MORE
Why DataCanvas
Little Giant
No. 1

World Champion

TOP3

Top 500

Innovation

SOLUTION
INDUSTRY & SCENARIO















Join hands with clients to move forward together
Through the AI Cloud in the Clouds strategy, DataCanvas works with cloud vendors and intelligent computing center partners to provide high-quality AI Foundation Services to the entire industry with AIFS products.













- Try AIFS:AI Foudation Software & Services
- Hotline:+86 400-805-7188
- E-mail:contact@zetyun.com
- Join Us:hr@zetyun.com














